
Welcome to our third installment of Hummingbird Labs, where we share our progress as we work to build compliance-grade AI. Today, we’re tackling one of the most commonly suggested AI use cases for compliance: using generative AI to automatically craft SAR narratives!
Working in the compliance industry, we’re deeply familiar with the Suspicious Activity Report (SAR). This report (and others like it) is filed by a wide variety of financial institutions around the world, and is the means by which suspicious financial activity is reported to law enforcement agencies. While SARs contain a large amount of hard data (transactions, accounts, locations, etc.), the most important part of the report is the narrative. Every SAR report features a narrative, written by the investigator handling the case. The report provides a detailed account of the suspicious activity and why the institution believes it merits law enforcement attention.
The narrative is not only the most important section of a SAR for law enforcement, it’s also the most time-intensive portion of a compliance investigation. Crafting a SAR narrative is complex and labor-intensive. It’s also not an area where institutions can rush things or allow for shortcuts – narrative quality is essential and is a major focus area for regulators and auditors.
When ChatGPT first hit the internet, the world was shocked by how well it could craft written material. Soon, folks had GPT writing clever limericks, composing romantic sonnets, and copying the style of classic writers. At Hummingbird, our ChatGPT experiments were a little more focused. We wanted to know: could ChatGPT be used to accelerate the crafting of high-quality SAR narratives? Could we feed an LLM model the details of some of our demo cases and ask it to write a narrative for each?
Because our team is made up of engineers and data scientists, we were optimistic. Because our team is also made up of compliance specialists, we were also deeply skeptical. ChatGPT is clearly quite powerful, but a SAR narrative is a very unique piece of writing. Instead of a piece of creative prose, it is a carefully constructed breakdown of a potential money laundering case, and contains many highly-specific details presented in a deliberate, highly-organized manner. SAR narratives need to be direct and to the point, concise but detailed.
But then again – you never know until you try. So we rolled up our sleeves, created an API key, and got coding.
🤔 tl;dr
A summary of what we’ve learned about GenAI for SAR narratives:
Good
Bad
Playing around with ChatGPT, our goal was to see how quickly we could build a SAR narrative generation feature. At this stage, our goal wasn’t perfection: this experiment was theoretical and would be based on fabricated case data. Instead, we wanted to focus on getting a version of the tool operational as quickly as possible. It’s a measure of how advanced some of these models are that it didn’t take long – we were up and running in a matter of hours. With our ChatGPT tool tuned and ready to go, we started to test it against the sample data.
Unfortunately, the results weren’t particularly promising. Functionally, the tool worked just fine, but the output was rife with hallucinations and errors. The AI would generate what looked like a reasonable SAR narrative, but upon closer inspection the narrative would reveal things that were entirely fabricated. The model would describe interactions between a subject and an institution that had never happened. It would describe a non-existent interaction with law-enforcement, or an in-person interaction at a bank branch (even though no bank branch information was included in the data).
Frankly, we weren’t terribly surprised by this. After all, hallucinations are a well documented phenomenon with LLM models. So, having discovered the hallucinations, we began to explore options to prevent them. First, we simply adjusted the code to tell ChatGPT not to make up facts, adding explicit instructions telling the model to avoid adding any information that wasn’t directly provided. This had little to no effect. The AI kept making up facts to fill in the narrative and make it more robust. We kept troubleshooting. What if we provided the AI more information? Could we fill the story out enough so the AI wouldn’t “feel the need” to make up facts? (Again, this was theoretical work done with dummy data, so we weren’t worried about our experiment exactly resembling a real world scenario.)
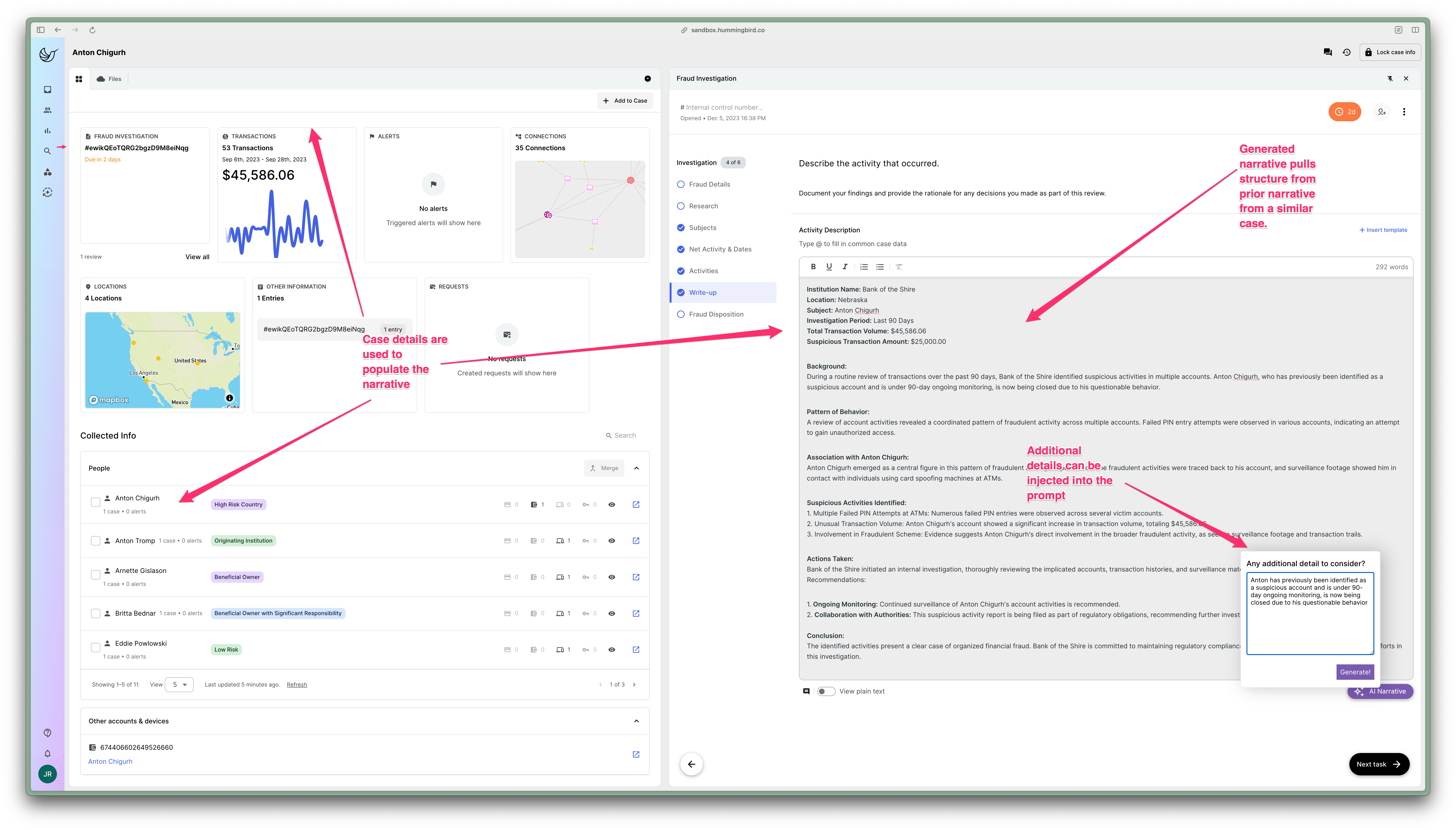
We added more information to the case, even adding a user prompt to allow the investigator to add additional insights that didn’t fit into the rest of the structured case data. Despite this, however, the AI was still too creative with it’s authoring, adding in unnecessary fictions.
We had also discovered another hiccup: relying on a prompt (which the investigator would have to present to ChatGPT) put a lot of pressure on the investigator. Different wordings resulted in significantly different generated narratives.
Finally, we thought to give the AI an example narrative from a prior, similar case. If the AI had a template to follow, we thought, it would be much more likely to know what we wanted. This worked wonders! Hallucinations become practically nonexistent, and the results started to look very reasonable. The AI effectively templatized the text from the prior case and then populated the same format with new details from the case in question.
But while feeding the model templates on which to base its narrative generation significantly improved the output, there were still problems that (in our opinion) made the use of current ChatGPT models for SAR narratives a non-viable path forward. One of our engineers succinctly described the problem when they said, “Even if we get the model to 99% accuracy, that 1% of doubt will force investigators to check every detail, of every case narrative.” Clearly, that wouldn’t work. Manually reviewing every detail of an auto-generated narrative would take an investigator even longer to complete than would simply writing the narrative themselves!
At this point, we could see a trajectory of how we could continue improving the model. Yet, was that improvement taking us to where we wanted to be? We paused to reflect on our original goal: were we using AI to help make Suspicious Activity Reports more accurate, secure, and efficient than what is being used today?
With fine-tuning and further prompt engineering, we felt confident that we could reach a point where we were able to generate narratives that were reasonably accurate. Despite this, however, the chance for falsehoods (no matter how slim!) presented an unsurmountable problem for compliance teams.
Talking to compliance leaders, it seems this opinion is shared by the broader compliance community. In both a formal survey (as well as more casual conversations during events and calls), compliance leaders agreed that narrative generation was one of the least impactful tasks to potentially automate.
Which left us asking the question – what should we be doing instead?
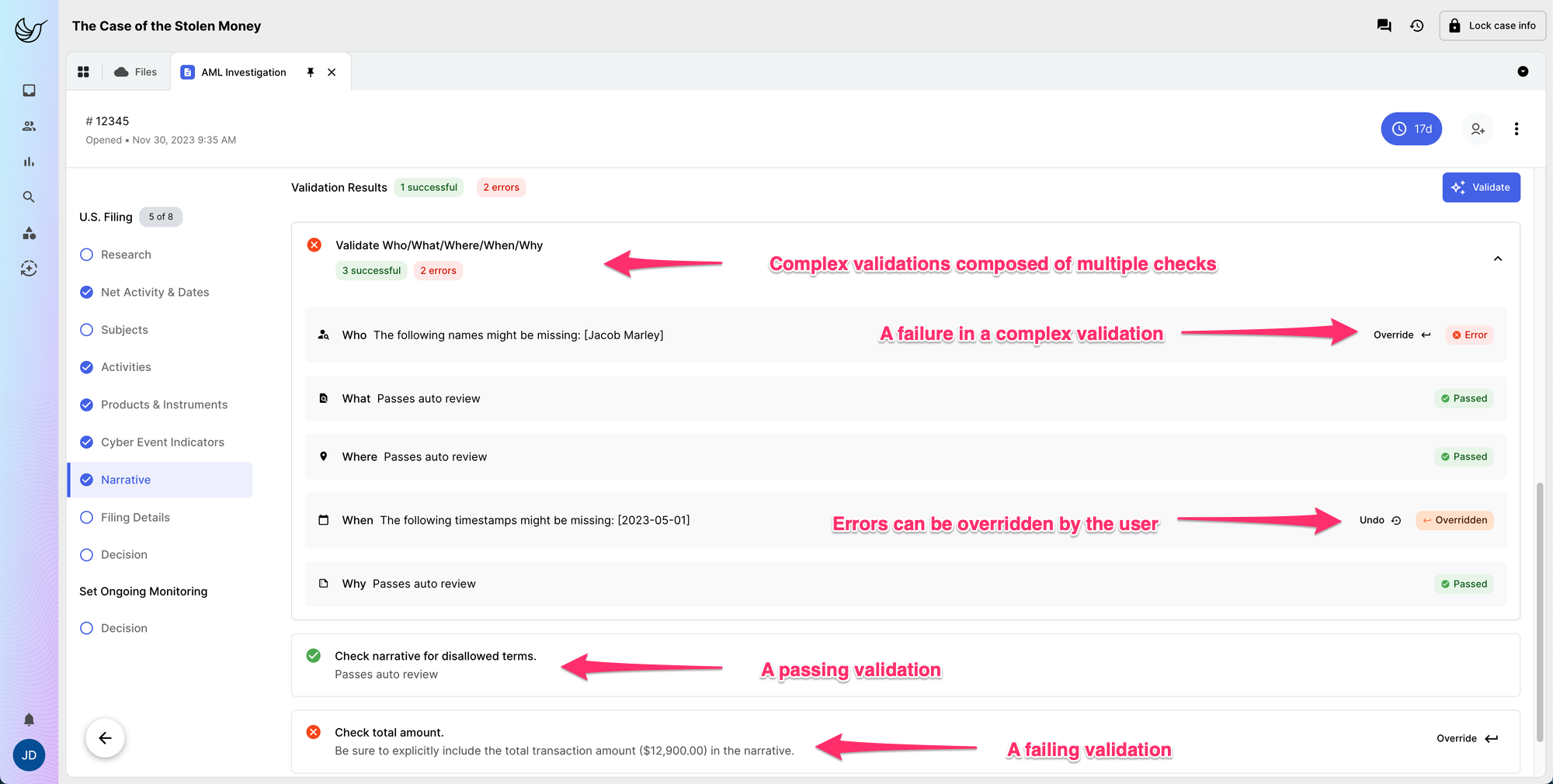
Having learned much from our efforts, we now asked a new question: was there another way to use AI to more efficiently craft a high-quality SAR narrative? Using the AI to craft the narrative had pushed the human investigator into an editorial role, something which, as we have seen, wasn’t going to be effective in the long run. But what if we swapped their roles? What if the AI became the editor, and instead of crafting the narrative, performed rapid quality checks on the investigator’s narrative, effectively peer reviewing the work?
A small team set off to build this exact tool, and early results are incredibly promising. Even our earliest prototypes are able to rapidly validate things like case subjects in the narrative, case activity with typology categorization, and to confirm that terms and phrases generally frowned upon are not used. We’ve also begun work to see how we could incorporate custom quality checks from plain text instruction. And that’s just the beginning. We get really excited as we imagine interpreting potential quality checks based on FIU guidance and institutional procedures.
Turning the problem on its head had given us an exciting new prospect: an AI editor that could easily fit into existing compliance workflows, accelerating work without adding unnecessary risk. With human investigators still focusing their skill and experience on the crafting, reviewing, and finalizing of SAR narratives, the AI editor provides assistance and accuracy validation. Rather than using AI to take over the crucial, human work of crafting a SAR narrative, this new tool employs AI to help improve case efficiency and ensure that every SAR sent to law enforcement is of the highest quality. It ends up looking like spell-check on steroids, but it’s a fast and efficient way to reduce the burden on writers and reviewers who currently spend hours double-checking work to catch minor issues that are easily caught by AI.
We haven’t abandoned the idea that AI may someday help with narrative generation. Far from it! But for the moment, our team continues to focus its efforts on developing AI tools that best meet the need for compliance teams working today. We’ll continue to monitor AI advancements and watch for improvements that make narrative composition a more compelling use case. In the meantime, we’re excited to work on bringing AI narrative validation to market, as well as exploring more AI tools for narratives. (Spoiler alert: we’re creating narrative templates that auto-populate with smart values from case data!). There’s a lot going at Hummingbird Labs, so stay tuned for updates on our newest products and latest generative AI experiments!
Subscribe to receive new content from Hummingbird

